Cloud Server Disaster Recovery (CSDR) provides remote disaster recovery protection for Elastic Cloud Servers (ECSs) and Bare Metal Servers (BMSs). Once the production center encounters a disaster, ECSs and BMSs protected by CSDR can be restored in the remote DR center.
In addition, ECSs and BMSs can be configured with active-active local storage to further guarantee zero data loss and service stoppage.
Table 1 compares characteristics of CSDR with those of traditional DR.
Characteristics |
CSDR |
Traditional DR |
|---|---|---|
Service configuration |
GUI-based service application and DR configuration, shortening the service enabling period from a week to half an hour |
Login to multiple devices and systems, and several times of configurations, consuming several days |
Security and performance |
|
Physical server deployment and agent installation on physical servers, deteriorating performance |
Cost effectiveness |
On-demand application and allocation and elastic expansion, reducing the initial investment |
One-off purchase of DR-dedicated storage, requiring a comparatively high investment |
CSDR functions:
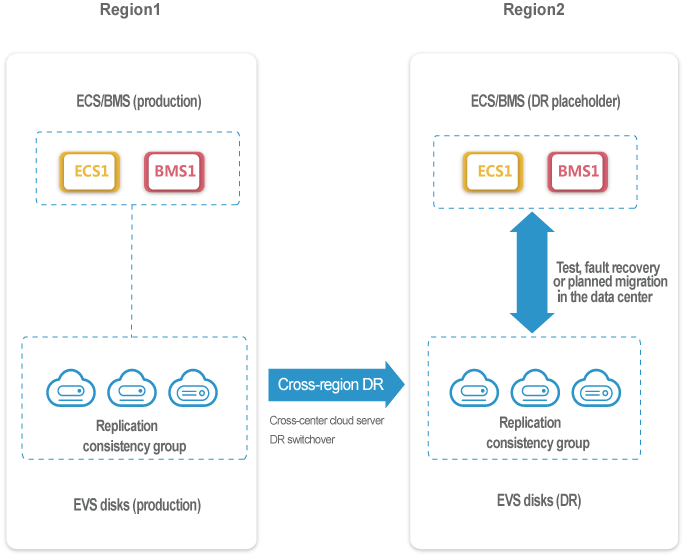
Tenants can apply for CSDR and add multiple ECSs/BMSs to a CSDR service instance to ensure remote replication consistency. Remote replication DR can be implemented in synchronous or asynchronous mode. CSDR can automatically perform scheduled remote replication on arrays according to configured remote replication policies.
Tenants can apply for DR tests to verify the data availability in the DR center. DR tests have no impact on the production center.
In the production center, when a planned power-off (planned power outage, or routine O&M), a DR administrator can perform planned migration of ECSs/BMSs by one click, ensuring zero data loss.
When the production center malfunctions due to a power outage, fire, or another disaster, a DR administrator can perform fault migration on ECSs/BMSs by one click to fast recover ECSs/BMSs to a DR center, minimizing impacts on services.
Figure 1 illustrates the working process of CSDR.
CSDR working process: